

The Harness, Not the LLM
What's actually driving your coding agent in 2026
When I wrote When the Vibes Begin to Fade, the central claim was uncomfortable for a lot of developers and product managers I spoke to afterwards: the large language model is rarely the bottleneck in an AI coding assistant. The harness around it is. Six months on, that argument has only sharpened — and quite a lot has happened in the tooling world that is worth revisiting in detail.
This article does three things. It revisits the four-layer model I introduced earlier, with a far more careful treatment of agentic tool use and of the often-overlooked fact that the "RAG model" inside a coding assistant is not the model that writes your code. It then takes stock of where we actually stand in 2026, focusing on two telling examples: Google's Antigravity and the quiet evolution of Cursor. Finally, it looks at where the field is heading next, with reference to a recent paper out of Tel Aviv University that, in my view, points the most credible way forward.
It is never "just the LLM"
When someone says "Cursor is amazing" or "Claude Code feels like magic", they almost always mean it as a statement about the underlying language model. That instinct is wrong. Every modern coding assistant is a composition of two very different things: a large language model on the one hand, and a substantial supporting apparatus — the harness — on the other. The harness is what decides what the model sees, when it sees it, what tools it is allowed to invoke, and how those tools are wired to your editor, your codebase and your build system.
You can verify this empirically without much trouble. Drop the same Claude Sonnet model into Cursor, then into Claude Code, then into a small custom agent you wrote yourself in an afternoon. The behaviour will differ wildly. The model is the same; the harness is not.
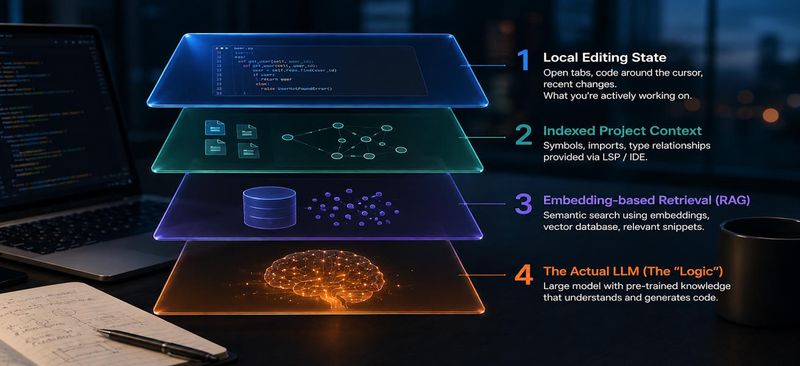
For the purposes of analysis, the harness in a modern IDE-integrated coding assistant naturally breaks down into four layers.
The four layers
Layer 1 — The local editing state. This is everything immediately under the developer's hands: open tabs, code surrounding the cursor, recently edited regions, perhaps a selection. It is the cheapest and most reliable signal the system has, because it does not require any retrieval at all — the editor already knows it.
Layer 2 — The indexed project context. This is the symbolic skeleton of the project: symbol definitions, imports, type relationships, references. It is usually surfaced via the IDE's Language Server Protocol, the same machinery that powers your "Go to Definition" and rename refactorings. LSP is mature, deterministic, and unfortunately limited to what static analysis can know — but for what it covers, it is rock solid.
Layer 3 — Embedding-based retrieval (RAG). This is where things get interesting and where most of the public discussion is concentrated. The codebase is chunked, embedded into vectors, and stored in a vector database. At query time, the user's question (or some derived intent) is embedded too, and the system uses it to look up semantically nearby fragments to load into the prompt. Cursor does this in the cloud against Turbopuffer; Roo Code lets you run the same kind of pipeline entirely locally with Qdrant and a small open-source embedding model such as nomic-embed-text.
There is a point about Layer 3 that I find is consistently glossed over, even in technical conversations. The embedding LLM is not the LLM that writes your code. It is a small, specialised model whose only job is to project text into a vector space such that similar things land close together. A typical local choice, nomic-embed-text via Ollama, fits in about a gigabyte of memory and runs comfortably on a developer laptop. It generates no code. It understands no control flow. It has no opinion about your architecture. It only measures similarity.
This matters because it places a hard ceiling on what semantic search can do for code. Embeddings preserve approximate meaning, not structure. They will happily tell you that AuthService is conceptually near LoginController, but they will not tell you that one calls the other, in which order, with what failure modes. The "intelligence" that people attribute to Cursor's semantic search is really borrowed credit; the heavy lifting happens later, in Layer 4.
Layer 4 — The actual large language model. Claude Sonnet, GPT-5, Gemini 3 Pro. This is the model with the vast pre-trained knowledge of programming languages, libraries, idioms and patterns. It does the reasoning, writes the code, holds (loosely) a model of your intent in context. It is also the only layer that scales with model size in the way the public expects: more parameters, more compute, broadly more capable.
In the language I introduced before: Layers 1–3 are the harness. Layer 4 is the LLM.
Agentic tool use: where the real leap happened
The four-layer breakdown is useful, but it understates how much things have moved on in the last twelve months. Until quite recently, a coding assistant would assemble Layers 1–3 into a single prompt and hand it to the LLM, which would generate a response. The LLM was passive. It received whatever context the harness chose to ship.
That model is gone. What replaced it is agentic tool use — and this, more than any single improvement in raw model quality, is what makes the current generation of assistants feel qualitatively different.
In an agentic setup, the model itself decides which tool it needs next. The harness exposes a menu — read a file, search by pattern, search by meaning, list a directory, run a test, run a build, edit a file — and the model picks. Crucially, it picks situationally. When the developer asks "where do we handle authentication?", the model recognises this as a vague, conceptual query and reaches for the compass: semantic search. When the developer asks "find every caller of User.save()", it recognises this as a precise structural query and reaches for the magnifying glass: a ripgrep query, or better, an AST-aware lookup.
Look at the published system prompt for Antigravity and you can see this design philosophy spelled out explicitly. The agent has tools called codebase_search (semantic, embedding-driven), grep_search (ripgrep, exact match), find_by_name (filename search via fd), view_file_outline (function and class outline of a file with line ranges and signatures) and view_code_item (read a specific function or method by fully qualified name, e.g. Foo.bar). The agent is free to call any of them in any order. It typically does so in a tight read → search → edit loop that closely mirrors how a competent human developer works on an unfamiliar codebase: form a hypothesis, explore, narrow down, change something, verify.
This is what I mean by tool use being qualitatively different from passive context assembly. The LLM is no longer being fed the project — it is investigating it.
What has changed since December: Antigravity and Cursor
In the original article I described the typical Layer 3 setup as embedding-based RAG over a cloud or local vector store, and I suggested that the deterministic richness of the IDE's Language Server was being underused. Six months later, both Antigravity and Cursor have moved in exactly the direction I argued for. It is worth examining in some detail.
Antigravity: not just RAG
Google released Antigravity in late 2025 as an "agent-first" IDE, built around Gemini 3 and a deliberately broad tool surface. Reading the public system prompt, the design language is clear. Antigravity does not present itself as a semantic-search product with an LLM bolted on. It presents itself as a competent investigator with a toolbox.
That toolbox is genuinely hybrid. There is codebase_search for semantic retrieval — RAG in the classical sense, with chunking, embeddings and a vector index. But the model is also given grep_search, which is ripgrep under the hood, returning JSON with filename, line number and matched content, capped sensibly at fifty matches. There is find_by_name, which delegates to fd. There is view_file_outline, which produces a structural outline of a source file — functions, classes, signatures, line ranges — and view_code_item, which lets the agent fetch a class or function by its qualified name, not by line range. These last two are the interesting ones: they are AST-aware. The agent can navigate a file the way a developer with a working "Go to Symbol" panel navigates it, rather than the way cat does.
There is also a knowledge-base mechanism — Antigravity lets the agent save useful context and snippets for future tasks — and a browser sub-agent that can drive a real browser session, log into things, click around, and report back. The combination is striking. Antigravity is not doing one thing well; it is presenting the model with several complementary ways to see the codebase and letting it choose.
In the framing of the original article, this is a system that has bound all four layers: editor state, structural / AST-aware navigation, embedding-based retrieval, and the actual LLM — and then handed the LLM agentic control over the lot.
Cursor: quiet sophistication
Cursor's evolution is less flashy but no less significant. The public narrative about Cursor is still mostly "they do clever embedding-based search". What Cursor actually runs is more elaborate than that.
Files are parsed locally with tree-sitter into an abstract syntax tree, and the chunking respects that tree — functions stay whole, classes stay whole, AST nodes get merged into sibling chunks only when they fit under a token budget. This is straightforward but consequential: it means Cursor's embeddings are taken over syntactically meaningful units, not arbitrary text windows that happen to slice through a function definition. The chunks are embedded server-side, with their vectors and metadata stored in Turbopuffer; importantly, the actual source code never leaves the local machine in the index — only the vectors and line ranges do. Local fingerprints, organised as a Merkle tree of file hashes, drive incremental updates: when a file changes, only the affected subtree is re-uploaded.
That much was already in place a year ago. What is newer is what Cursor has done with plain text search. The Cursor engineering team has written publicly about hitting the limits of ripgrep itself — single rg invocations were taking over fifteen seconds on the largest monorepos they support — and responding by building a custom regex index on top of a sparse n-gram scheme backed by mmap. The result is millisecond-level regex queries over enormous codebases. From the agent's point of view this is invisible plumbing, but it is the same intellectual move as Antigravity's design choice: take the deterministic, lexical tools seriously, make them genuinely fast, and let the model use them alongside the probabilistic ones.
In short, Cursor has converged on the same hybrid stance: tree-sitter for structure, custom-built regex search for precision, embeddings for semantic recall, and an agentic loop on top that decides which to use when. The Language Server is no longer ignored either — Cursor consumes LSP signals for diagnostics and incremental edits, even if the public marketing rarely mentions it.
Hybrid search has quietly won
Step back from the individual products for a moment and the underlying pattern is hard to miss. Every serious coding agent in 2026 — Claude Code, Cursor, Antigravity, Cline, Aider, Continue — runs a hybrid search stack. Ripgrep or a custom equivalent for lexical certainty. Tree-sitter (or, increasingly, language servers) for structural navigation. Embeddings for fuzzy conceptual recall. The agent picks among them via tool use.
Recent empirical work has reinforced why this matters. Several preprints over the last few months have measured the actual effectiveness of pure semantic RAG for code-specific tasks and found, bluntly, that it underperforms. Short keyword queries of the kind developers naturally produce — auth flow, user service, handle error — collapse most semantic models tested to near-zero nDCG@10. Vector search alone, without lexical and structural reinforcement, is not a viable retrieval strategy for code.
This vindicates a point I made in the original piece almost in passing: embeddings preserve approximate meaning, not structure. We now have a year of production data agreeing with that.
What is still missing: deterministic architectural maps
Even a well-tuned hybrid system has a blind spot. Tree-sitter gives you the syntactic structure of one file at a time. The Language Server gives you symbols, types and references — extremely useful, but limited to what the language tooling can resolve, and traditionally weak across language boundaries. None of these layers tells the agent what your build and test topology actually looks like. Which executables exist. Which libraries link against which. Which tests cover which components. Which external packages are pulled in by which module. That information lives in CMake files, Maven POMs, Cargo manifests, npm workspaces, Go modules — and your agent currently reverse-engineers it on the fly, expensively and unreliably, every time it enters the repository.
A recent paper out of Tel Aviv University by Cherny-Shahar and Yehudai (Repository Intelligence Graph: Deterministic Architectural Map for LLM Code Assistants, arxiv 2601.10112) is the most credible attempt I have seen to close this gap. Their proposal is two-part. SPADE is a deterministic extractor that walks your build and test artefacts — for CMake, it uses the CMake File API and CTest metadata directly — and emits a graph called the Repository Intelligence Graph (RIG). Nodes are components, aggregators, runners, tests, external packages and package managers; edges are dependencies, coverage relationships and package usage. The graph is serialised as JSON and injected into the agent's context at the start of the session.
Crucially, none of this is probabilistic. RIG is evidence-backed. Each node and edge traces back to a concrete artefact in your build system. The agent does not have to guess at the architecture; it can look it up.
The measured effect is significant. Across eight repositories of varying complexity, and across three commercial agents — Claude Code, Cursor and Codex — providing RIG in context improved structural accuracy by 12.2 % and reduced wall-clock completion time by 53.9 % on average, with efficiency gains rising to 69.5 % on the more complex multilingual repositories (all figures: Cherny-Shahar & Yehudai 2026, Abstract / §VI). The authors note, sensibly, that the gain is largest precisely where it ought to be: on complex, multi-language projects where reverse-engineering the build topology is most expensive.
Putting SPADE to work today
SPADE is open source on GitHub under Greenfuze/Spade. There is no official plugin or agent yet, and you do not need one for an initial trial. The practical workflow is straightforward.
Run SPADE locally against your repository. For CMake projects, this works automatically; for Maven, npm, Cargo or Go projects, you currently author the RIG by hand against the same schema. Save the JSON output somewhere stable in your tree, for instance .rig.json. Reference that file from your CLAUDE.md, your Cursor Rules, or whichever mechanism your agent uses to ingest project-level context, and instruct the agent to treat the RIG as the authoritative description of the build and test structure — to consult it before falling back to file exploration.
The obvious next step is to wrap SPADE as an MCP server, so the agent can both query RIG entries on demand and regenerate the graph when the build system changes. The authors flag this as a design option (Cherny-Shahar & Yehudai 2026, §II-B) but do not implement it themselves. It is a satisfying weekend project for anyone whose codebase is large enough to feel the pain SPADE is meant to address.
A practical reading of all this
If you take only one thing from this article, let it be the same thing I emphasised in the original: the harness, not the LLM, decides how useful your coding agent will be on your codebase. The LLM in your assistant is, increasingly, a commodity. Claude Sonnet, GPT-5 and Gemini 3 Pro are all extremely capable, and switching between them rarely changes the experience as much as one would expect. What changes the experience is what the harness gives the model to see and to do.
A practical reading, for teams that depend on these tools at work:
You should care more about the tool surface of your agent than about which model it routes to. An assistant that can grep, AST-navigate, semantically search, and reason from a deterministic project graph will outperform one that has only embeddings, regardless of model size.
You should treat embeddings as one input among several, not as the input. Hybrid wins. If you are building your own agent, do not skip the boring lexical and structural tooling in favour of a clever vector store. Ripgrep and tree-sitter are still pulling more than their weight.
You should give your agent a project-level "map" wherever you can. CLAUDE.md, Cursor Rules, GEMINI.md, or a SPADE-generated RIG — anything that reduces how much the agent has to reverse-engineer your codebase pays for itself within hours. The MCP ecosystem is the natural carrier for this kind of curated, deterministic context, and I expect the next eighteen months to see far more of it.
And finally, you should keep a healthy scepticism about claims of "infinite context windows" and similar shorthand. The numbers may be technically true, but the effective working context — the slice of your codebase that the model actually reasons over at any moment — remains finite, costly, and shaped overwhelmingly by harness choices. That is where the next round of progress will come from. It is also where the design decisions you make today, as a team or as a tool vendor, will matter most.
A previous piece in this series, When the Vibes Begin to Fade, introduced the four-layer model and discussed the systemic limits of probabilistic generation in detail.
References
- Cherny-Shahar, T., & Yehudai, A. (2026). Repository Intelligence Graph: Deterministic Architectural Map for LLM Code Assistants. arxiv:2601.10112. https://arxiv.org/html/2601.10112v1
- SPADE (open source). https://github.com/Greenfuze/Spade
- Google. Build with Google Antigravity, our new agentic development platform. Google Developers Blog. https://developers.googleblog.com/build-with-google-antigravity-our-new-agentic-development-platform/
- Antigravity system prompt (community capture, December 2025). https://gist.github.com/anthfgreco/87718fbbf313bcf7f5ca3f36fedb372a
- Cursor. Securely indexing large codebases. https://cursor.com/blog/secure-codebase-indexing
- Cursor. Fast regex search: indexing text for agent tools. https://cursor.com/blog/fast-regex-search
- How Cursor Actually Indexes Your Codebase. Towards Data Science. https://towardsdatascience.com/how-cursor-actually-indexes-your-codebase/
- Why Cursor, Claude Code, and Devin Use grep, Not Vectors. MindStudio. https://www.mindstudio.ai/blog/is-rag-dead-what-ai-agents-use-instead
